

Prompting: Ein Sprachkurs für Maschinen
Vielleicht hast du schon mal ChatGPT ausprobiert und warst enttäuscht. Du hast gefragt: „Schreib mir eine Einladung für meinen Geburtstag.“ Die KI hat geliefert – aber der Text klang hölzern, förmlich und gar nicht nach dir.Der Fehler lag in der „Bestellung“. Der Fachbegriff für deine Eingabe ist Prompt. Und die Kunst, gute Eingaben zu schreiben, nennt man Prompt Engineering. Das klingt kompliziert, folgt aber einer simplen Formel.Die goldene Formel für den perfekten Prompt
Ein guter Befehl an die KI besteht fast immer aus drei bis vier Bausteinen. Stell dir vor, du gibst einem Koch eine Bestellung auf.- 👤 Die Rolle (Wer?): „Du bist ein erfahrener Event-Manager.“
- 📝 Die Aufgabe (Was?): „Schreibe eine Einladung für meinen 70. Geburtstag.“
- 🎨 Der Stil (Wie?): „Der Ton soll herzlich, lustig und nicht steif sein.“
- 🎯 Das Format (Womit?): „Der Text soll kurz sein und sich gut für WhatsApp eignen.“
Vorher vs. Nachher
Schlechter Prompt: „Schreib eine Einladung.“
(Ergebnis: „Sehr geehrte Damen und Herren, hiermit lade ich Sie herzlich ein…“) -> Langweilig.Guter Prompt: „Du bist mein bester Freund. Schreib eine kurze WhatsApp-Nachricht für meine Grillparty am Samstag. Mach einen Witz über das Wetter und sag, dass es Bier gibt.“
(Ergebnis: „Hey Leute! Samstag wird gegrillt – egal was der Wetterbericht sagt, ich habe genug Bier, um uns den Regen schönzuteinken! Kommt ab 18 Uhr vorbei!“) -> Treffer.
Beispiel für Fortgeschrittene: Eine Mängelrüge verfassen
| ❌ Zu einfacher Prompt | ✅ Profi-Prompt (Detailliert) |
|---|---|
| „Schreib eine Beschwerde an den Handwerker, weil die Heizung nicht geht.“ | Rolle: Du bist ein erfahrener Hausbesitzer, der seine Rechte kennt. Aufgabe: Verfasse eine formelle schriftliche Mängelrüge an die Firma ‚Sanitär Müller‘. Kontext: Die neue Wärmepumpe (installiert vor 2 Wochen) fällt ständig aus (Fehlercode E-404). Telefonisch wurde ich bereits dreimal vertröstet. Tonfall: Bestimmt und sachlich, aber nicht aggressiv oder beleidigend. Ziel: Setze eine klare Frist zur Nachbesserung von 10 Werktagen. Erwähne, dass ich sonst rechtliche Schritte prüfe. Format: Formeller Briefstil. |
Der Unterschied
Der einfache Prompt liefert oft einen wütenden, unsachlichen Text („Ich bin sauer!“). Der Profi-Prompt liefert ein Schreiben, das man so sofort abschicken kann und das ernst genommen wird.
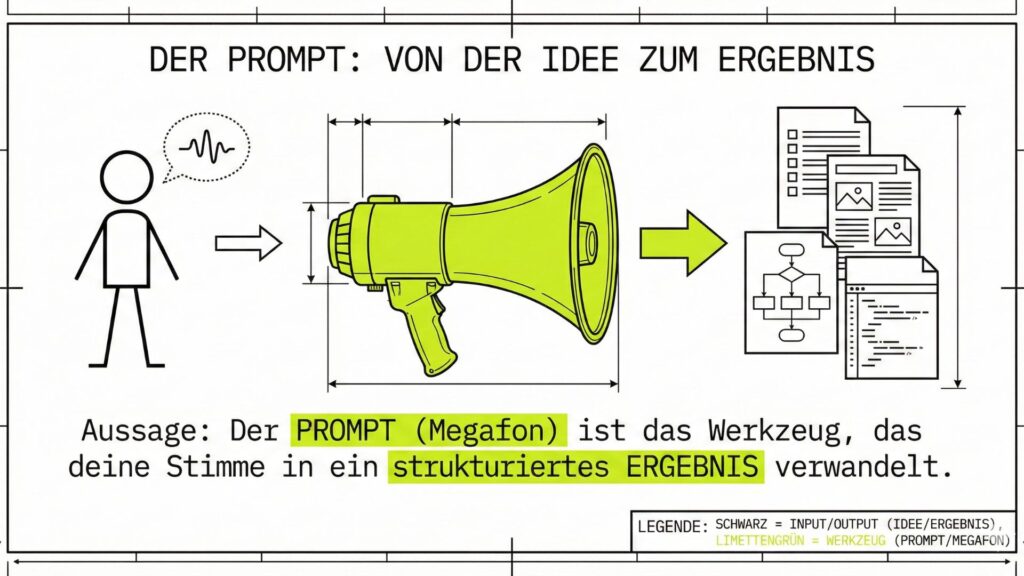
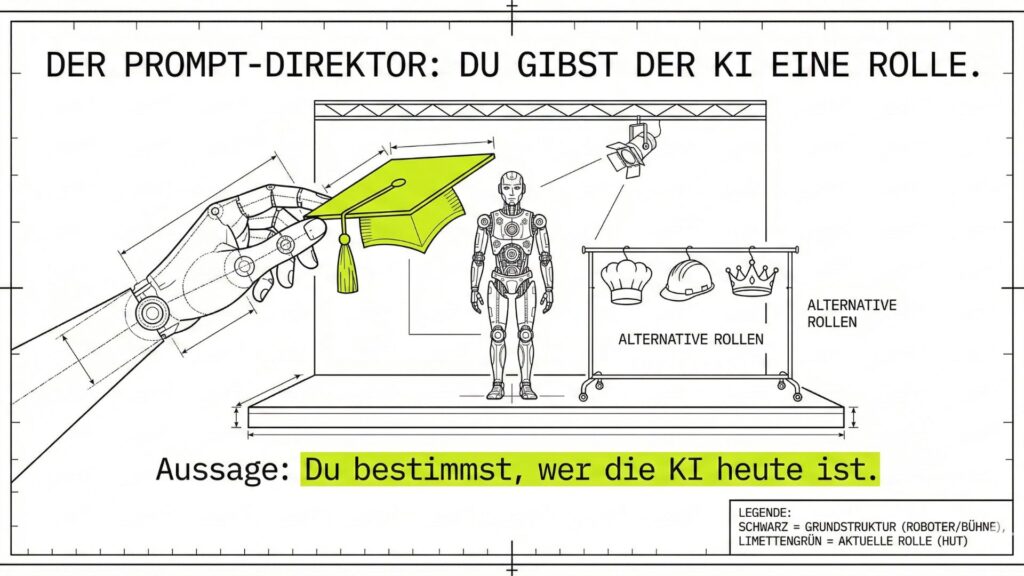
Die KI ist vergesslich – gib ihr Kontext!
Das größte Missverständnis ist, dass die KI weiß, wer du bist. Weiß sie nicht. Sie weiß nicht, dass du in München wohnst, dass du gerne kochst oder dass du Enkel hast – es sei denn, du sagst es ihr.Wenn du fragst: „Was soll ich kochen?“, kriegst du Standard-Antworten (Nudeln). Wenn du sagst: „Ich habe noch Zucchini, Eier und alten Käse im Kühlschrank. Was soll ich kochen?“, kriegst du ein kreatives Reste-Rezept.Der Dialog: Es ist keine Einbahnstraße
Viele Nutzer machen den Fehler, nach der ersten Antwort aufzuhören. Aber die KI ist ein Chat-Bot. Du kannst (und sollst) mit ihr reden!Wenn dir der Text nicht gefällt, sag es ihr:- „Das ist zu förmlich. Mach es lockerer.“
- „Kürze das auf die Hälfte.“
- „Erkläre mir Punkt 3 nochmal genauer, als wäre ich 10 Jahre alt.“
Gefahren beim Prompting
Auch beim besten Prompting gilt: Vorsicht mit privaten Daten. Da deine Eingaben oft genutzt werden, um die KI weiter zu trainieren, solltest du niemals Geheimnisse verraten.Sicherheits-Regel
Schreibe niemals echte Namen, Adressen, Passwörter oder medizinische Diagnosen in den Chat.
Statt „Mein Enkel Max hat ADHS, was kann ich tun?“ schreibe lieber: „Ein fiktives Kind hat Konzentrationsprobleme in der Schule, welche pädagogischen Strategien gibt es?“
Glossar: Prompting-Begriffe
| Begriff | Erklärung |
|---|---|
| Prompt | Die Eingabe (Textbefehl), die du in das Chat-Fenster tippst. |
| Kontext | Die Hintergrund-Infos, die du der KI gibst (z.B. „Ich bin Anfänger“, „Es ist für einen Brief“). Ohne Kontext rät die KI nur. |
| Rollen-Spiel | Der KI eine Identität geben („Du bist ein Reiseführer“), um bessere Antworten zu erhalten. |
| Iterieren | Das schrittweise Verbessern der Antwort durch Nachfragen („Mach es kürzer“, „Ändere den Ton“). |
Weiterführende Informationen
Interne Links
- vorheriges Kapitel – Was kann KI und was nicht? (Der Realitätscheck)
- nächstes Kapitel – Wer trägt die Verantwortung? (Ethik & Haftung)
